Agentic AI is leading a research revolution. Most social scientists have already integrated AI in their workflows, through individual experimentation and the grapevine of department corridors. However, uneven and heterogeneous uptake poses significant risks to individual researchers as well as to the whole of the research enterprise. This paper+website+repository is at once a practical manual for using agentic AI effectively and responsibly as well as a conversation-starter for thinking about the next chapter of research in the social sciences.
📄 Read the current draft 💾 Replication package 🧰 AI OS starter library 🎤 Workshop Prep
We need best practices and shared norms
Adoption has outrun shared practice and norms. Agentic AI raises two distinct questions for the research community.
How to reduce AI error?
Using AI effectively while reducing error. Every new method comes with new failure modes, and the familiar task is to learn them, build the routines that catch them, and codify what works. The paper's first half lays out a five-layer workflow stack — tool, harness, context, prompt, agent management — that does exactly this.
How to retain control?
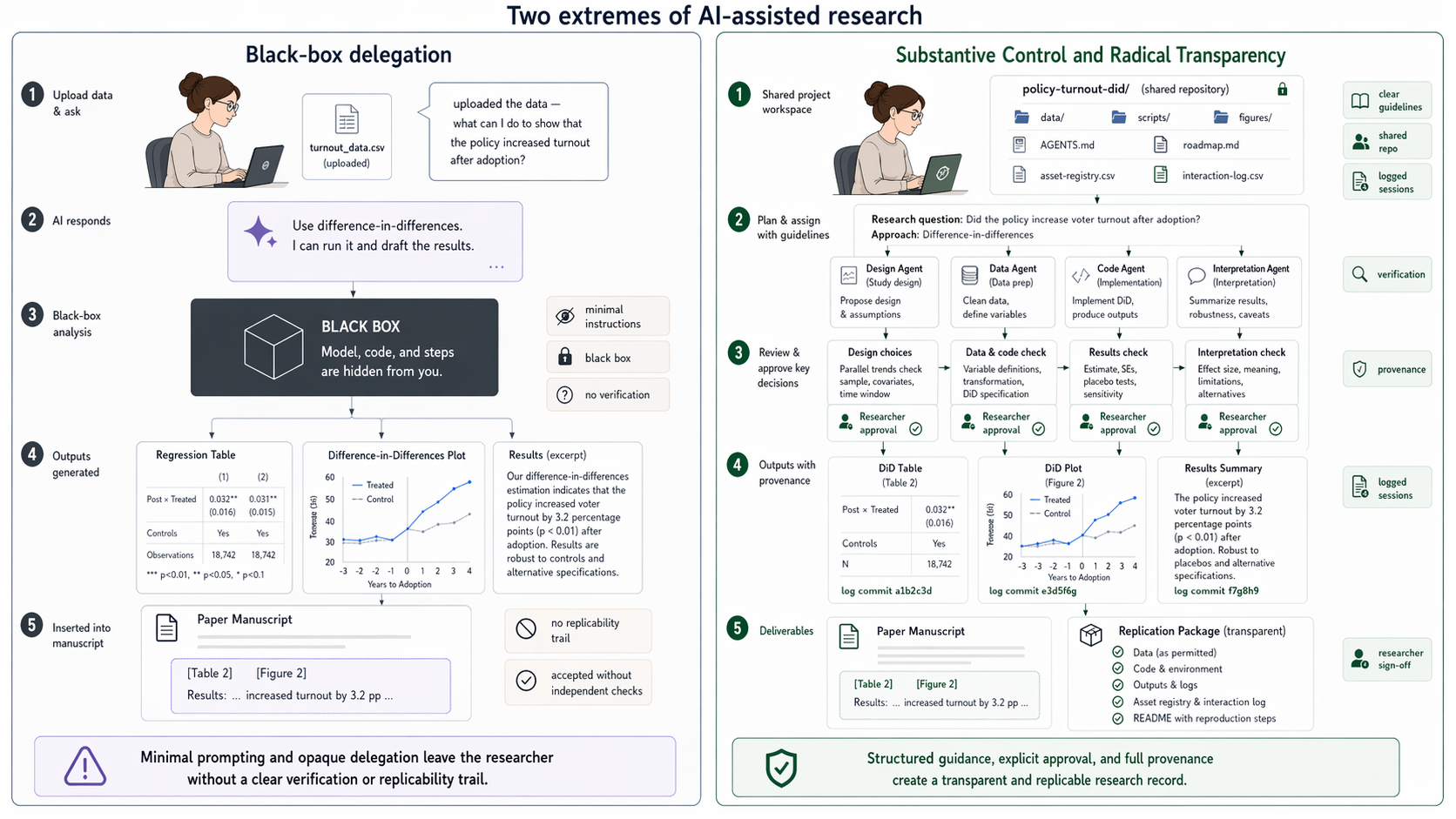
Using AI responsibly and transparently. This is genuinely new. Agentic AI is the first methodology that takes agency in the research process — drafting, executing, deciding. It shapes not just the error rate of findings but the direction of research itself. That demands norms the field does not yet have. The paper's second half — Governance — proposes two: researcher control over every substantive decision, and radical transparency over the AI-assisted process.
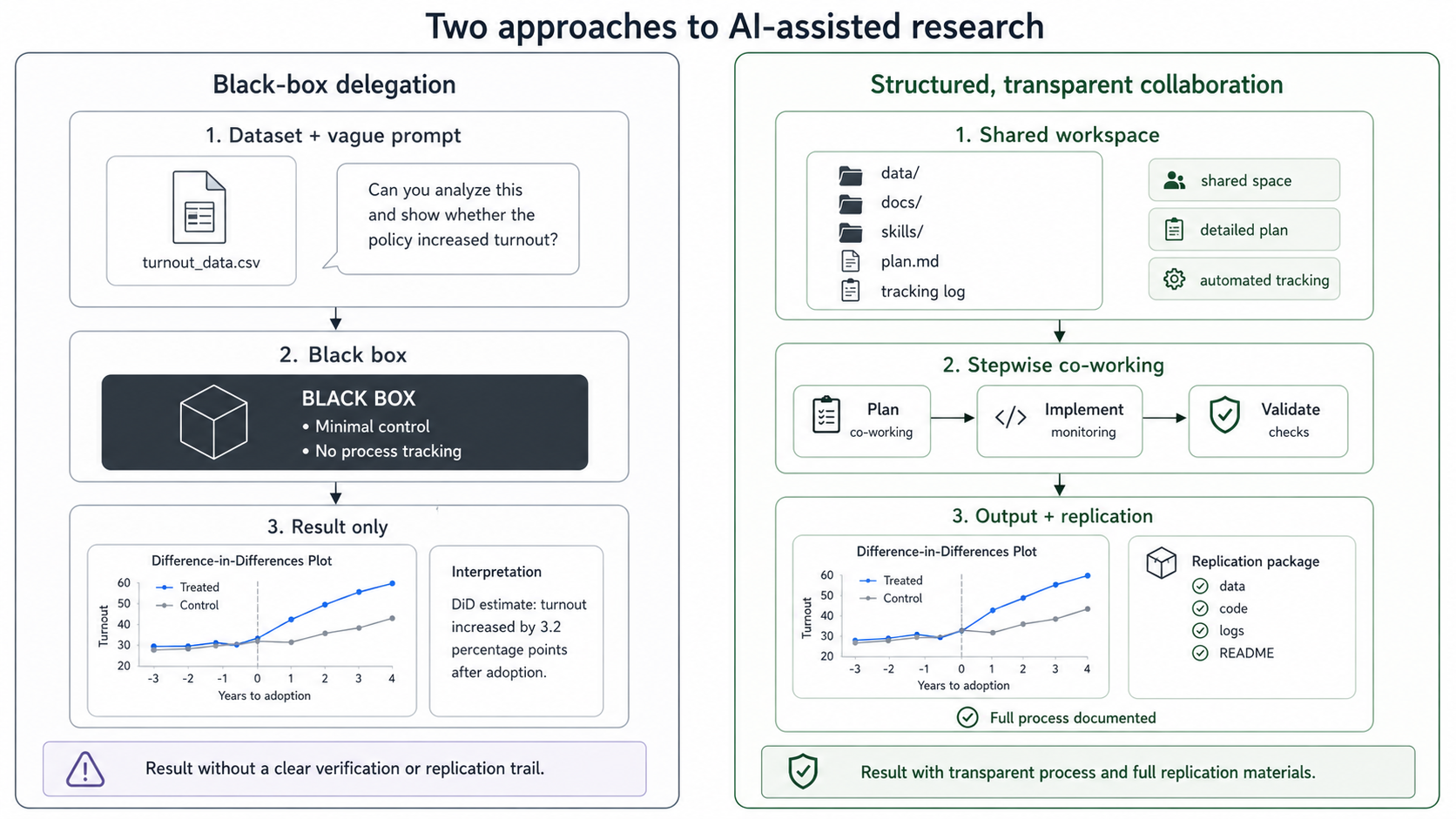
The setup stack
The paper proposes a five-layer workflow. Each layer conditions the ones below it — tool choice determines which harnesses can exist on top; the harness determines which skills and tools the agent can reach; and so on down to agent-level management across the research process.
Setting up AI agents in the research process.
Skills as the central artifact
Inside any harness, the highest-leverage object is the skill library: a persistent, personal repository of reusable procedures an agent can invoke on demand. Skills transcend any single project and should be built through a disciplined procedure combining external sources with the researcher’s own tacit knowledge.
A procedural approach to skill-building.
Context engineering in practice
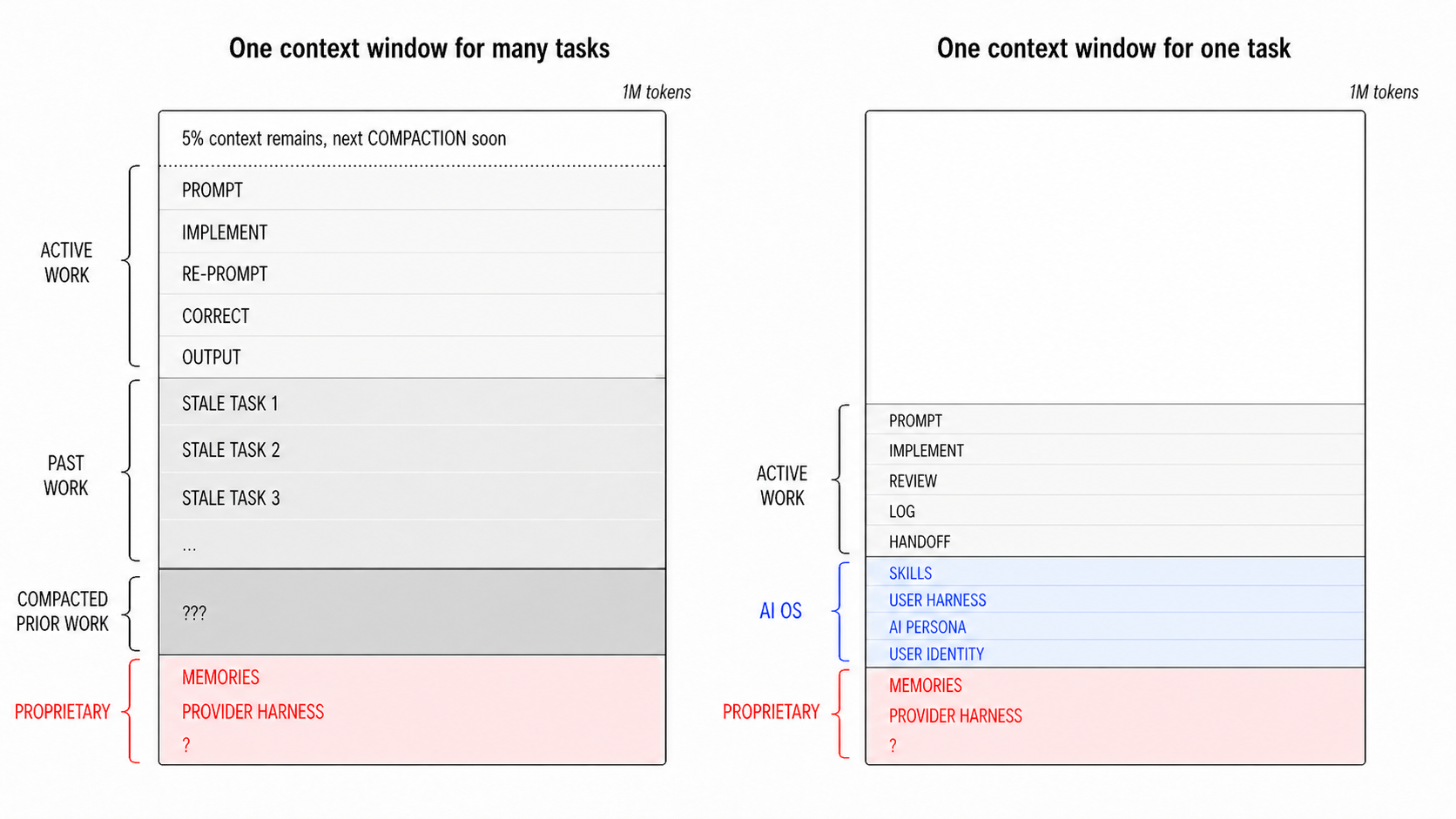
Every agent run consumes a finite context window. Once it fills, the model starts forgetting earlier instructions, dropping constraints, and drifting between the unrelated tasks loaded into the same session. The discipline is to treat each model instance as cheap and replaceable: persistent knowledge lives in the project folder, not in the chat. A new session starts from a clean slate, pulls only what the task at hand requires, and runs a tight plan → instruct → verify → correct loop on artifacts the next instance can re-read.
That same project folder is what makes radical transparency possible. It doubles as a sandbox repository — a single directory carrying everything the agent needs (background concepts, literature, data, scripts, feedback) and a record of how each piece got there. Every asset is flagged for provenance (human / agent / mixed) and verification (not-verified / partially-verified / human-verified); every non-trivial agent session is logged. The replication package now documents the AI’s role — not just the final data and code.
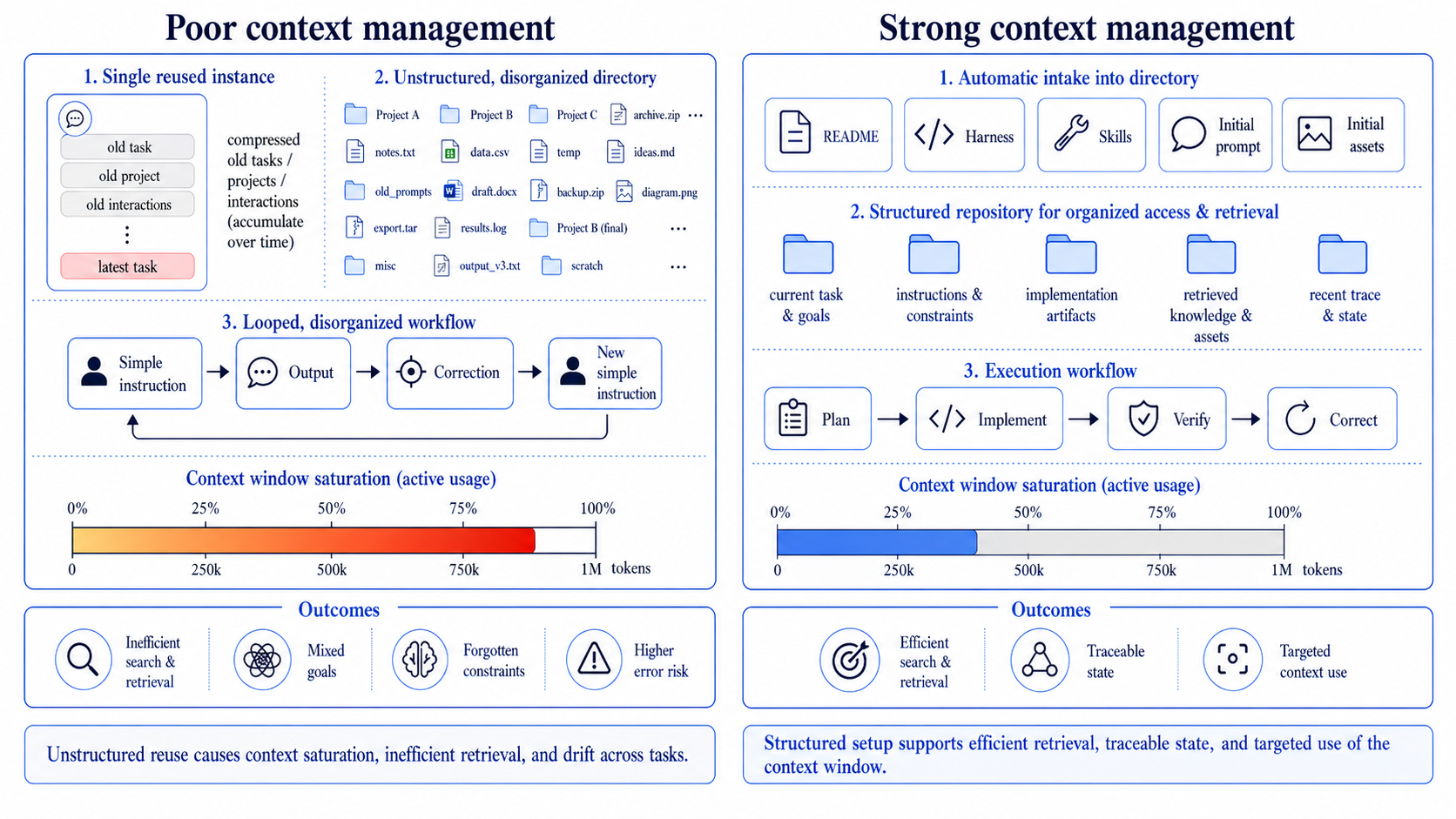
project/
README.md
implementation-roadmap.md
asset-registry.csv
interaction-log.csv
background/
literature/
concepts/
feedback/
archive/
drafts/
data/
figures/
tables/
scripts/
appendix/
- Verification flags on every major asset:
not-verified,partially-verified,human-verified. - Provenance flags:
human,agent, ormixedfor each asset entry. - Interaction log summarizing every non-trivial agent session (date, input, output, model metadata).
- Archive pattern: obsolete files move to a local
archive/rather than being deleted. - Project-setup skill scaffolds the above structure in a single invocation.
A sample project context setup.
Two governing principles
Researcher control
Every substantive decision — framing, empirical design, interpretation, final phrasing — stays with the researcher. Execution may be delegated; ownership and judgment cannot.
Radical transparency
A credible replication package must now extend to the inputs, throughputs, and outputs of the AI-assisted process itself — not just data and code.
Both governing principles need to bite at the operational level. Substantive control means drawing a hard line between procedural work that may be delegated and substantive judgment that must not — and operating accordingly. Radical transparency means treating the project folder as the audit trail and releasing it as part of the replication package.
How to decide when to use AI?
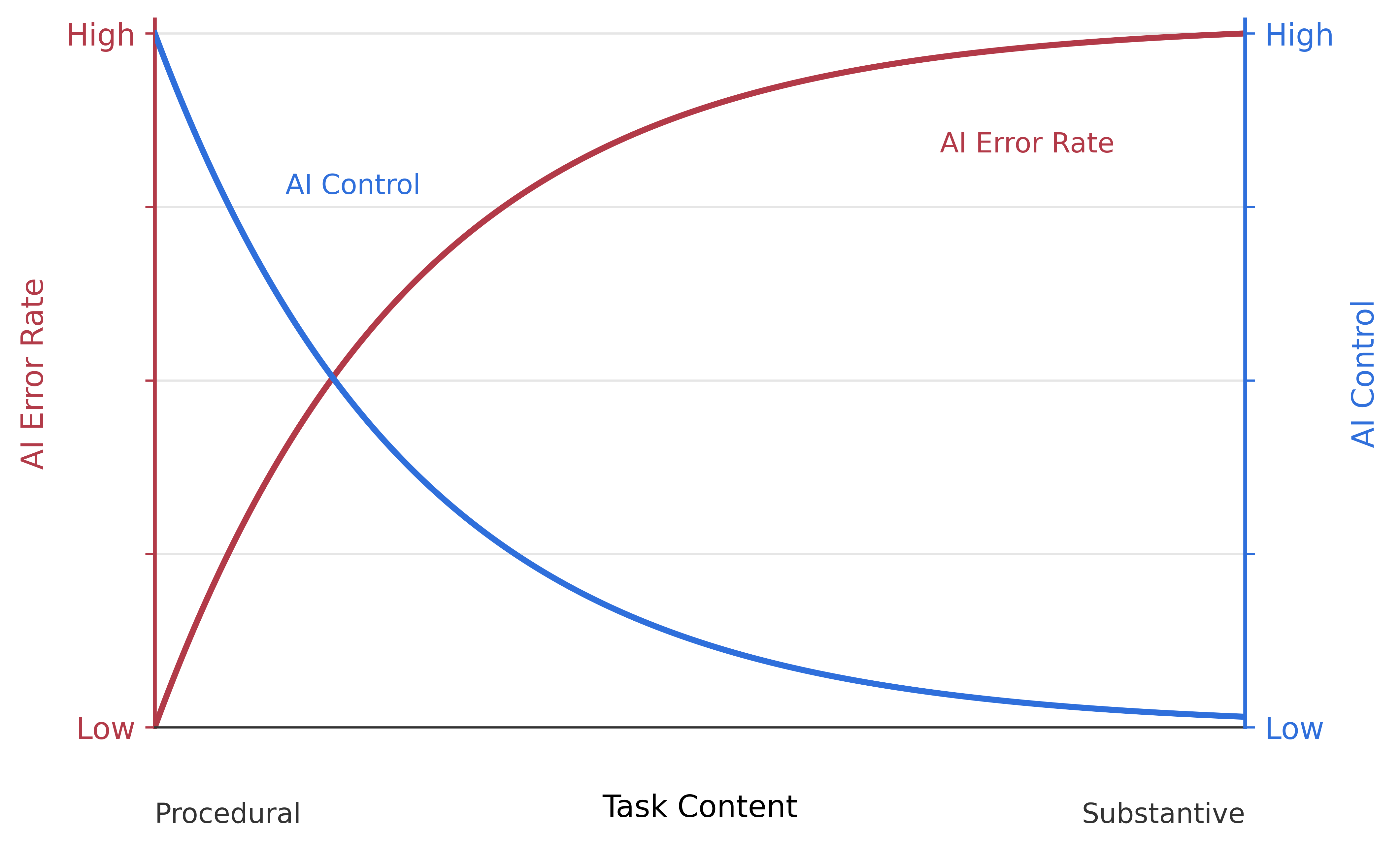
Before delegating any task, ask one question: is the work procedural or substantive? Procedural tasks are rote — the same steps repeated across projects, by many people, with a checkable target. Substantive tasks rely on knowledge that is idiosyncratic to your project: your question, your data, your priors, your interpretation. Agents excel at the former because they have seen the pattern many times. They fail at the latter because, with no idiosyncratic knowledge to retrieve, they fill the gap with plausible-sounding fabrication.
Procedural — delegate
Why it works. Rote tasks repeat across projects; the model has seen the pattern many times. Output is checkable against a known target.
- code a specified estimation pipeline
- format tables and figures from results
- convert between data or document formats
- draft boilerplate sections (methods, data documentation)
- compile references on a keyword
Substantive — keep with the researcher
Why it fails. The required knowledge is idiosyncratic to this project — your question, your data, your priors. With nothing to retrieve, the model fills the gap with plausible-sounding fabrication.
- decide the research question
- choose which assumptions to make
- choose the identification strategy
- interpret coefficient estimates
- decide the central claim
How to report when AI was used?
Releasing data and code is no longer enough. When agents have drafted, decided, or executed parts of the work, a credible replication package must extend three layers further — to the inputs, throughputs, and outputs of the AI-assisted process itself:
- Inputs — the prompts, plans, and context materials given to the agent.
- Throughputs — the agent’s reasoning, intermediate outputs, and sign-off gates.
- Outputs — final artifacts tagged with model and version metadata.
The paper proposes a feasible, low-friction implementation: two CSV ledgers maintained inside the project folder. An asset registry flags every artifact’s provenance (human / agent / mixed) and verification status; an interaction log summarizes every non-trivial agent session (date, input, output, model metadata). The project folder itself, with the ledgers inside it, becomes the audit trail.
The cost is real — authors log, register, and verify; reviewers read, cross-check, and judge. The consoling point is that the same tools that raise the bar also help meet it: interaction logs are written in-session rather than reconstructed afterward, and asset registries are updated by the same agents that produce the assets.
What’s in the replication package
This site’s companion repository is the project folder used to write the paper — released as a working replication package so readers can inspect every artifact, its provenance, and the full interaction history.
appendix/
Online appendix. Every asset cited in the main text, including the dogfooded skills: startup-checklist, self-interview-example, project-setup, project-setup-existing, skill-writing, lit-review-protocol, skills-library-setup, skills-library-connection.
drafts/
Paper drafts, including the agent-produced first draft and the latest compiled PDF.
background/
Literature notes, concepts, feedback. background/literature/ is Zotero-compatible BibTeX with per-source classification.
figures/, tables/, scripts/
Figures, tables, and demo code referenced in the paper.
asset-registry.csv
Every artifact with provenance flag (human / agent / mixed) and verification status.
interaction-log.csv
Every non-trivial AI-assisted session from inception through final draft.
AGENTS.md
Rules-of-engagement for AI agents in this folder. Dogfoods the paper's own control / transparency principles.
implementation-roadmap.md
Living to-do list used during writing — the entry point for any new agent session.
Companion: AI OS scaffolding
The disciplined workflow this paper advocates is not specific to this project. It generalizes — across papers, teaching, advising, business — into a personal AI Operating System layered on top of a coding-grade harness like Claude Code. The public-tier components of Simone’s setup are released as a starter library: protocol skills, five session-level personas (chief-of-staff, researcher, writer, engineer, teacher), and a librarian subagent for skill resolution.
It is methodology and governance scaffolding to fork and customize, not a turnkey product. A setup guide for Claude Code (terminal) ships now; Claude desktop and Codex entry points are forthcoming.
🧰 AI OS starter library on GitHub
Citation
Paci, Simone (2026). With Great Powers: A Practical Guide to Agentic AI for Social Science Research. Working paper. Replication package: github.com/simonepaciphd/with-great-powers
Contact
Simone Paci · Stanford University · spaci@stanford.edu